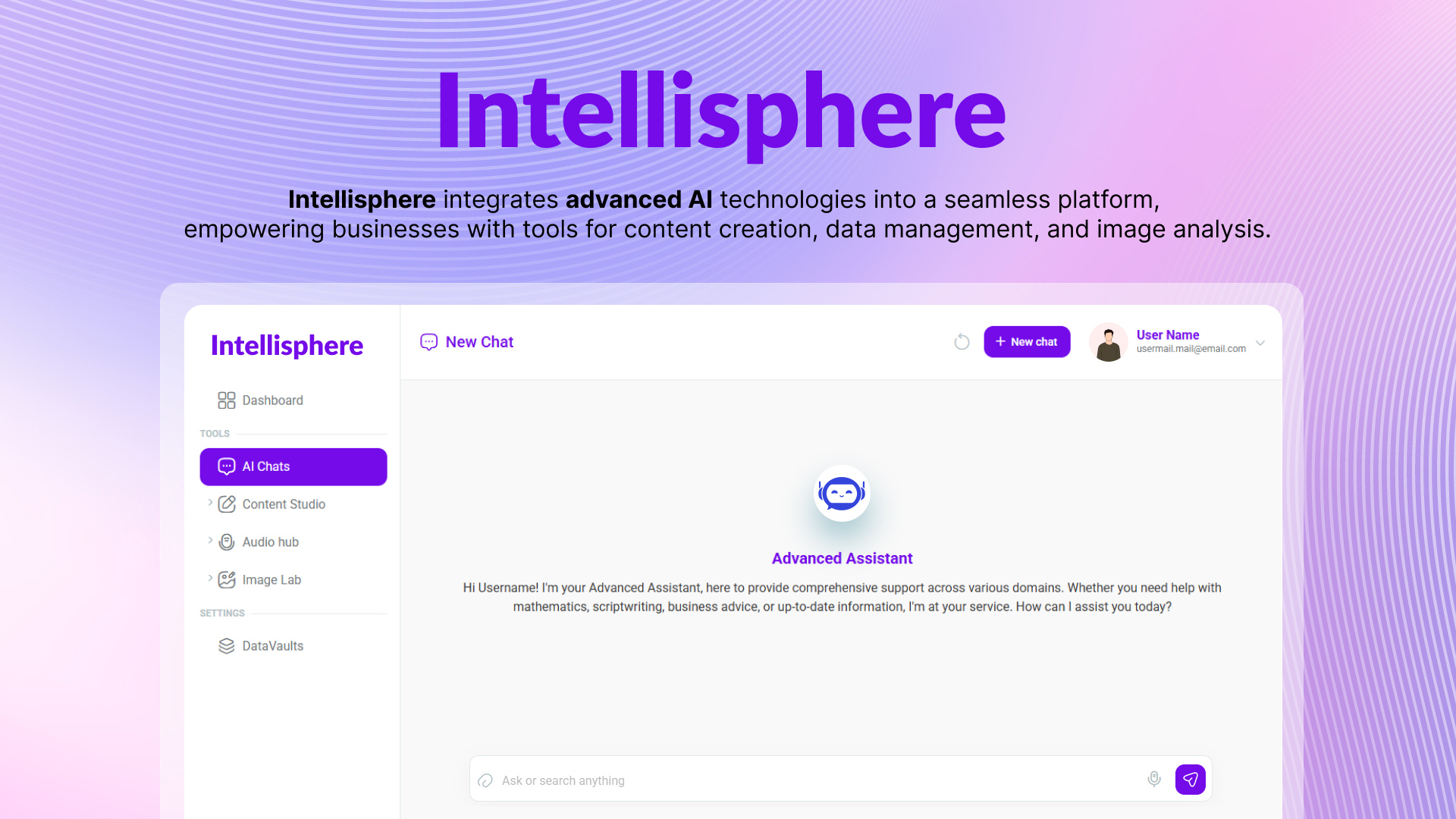
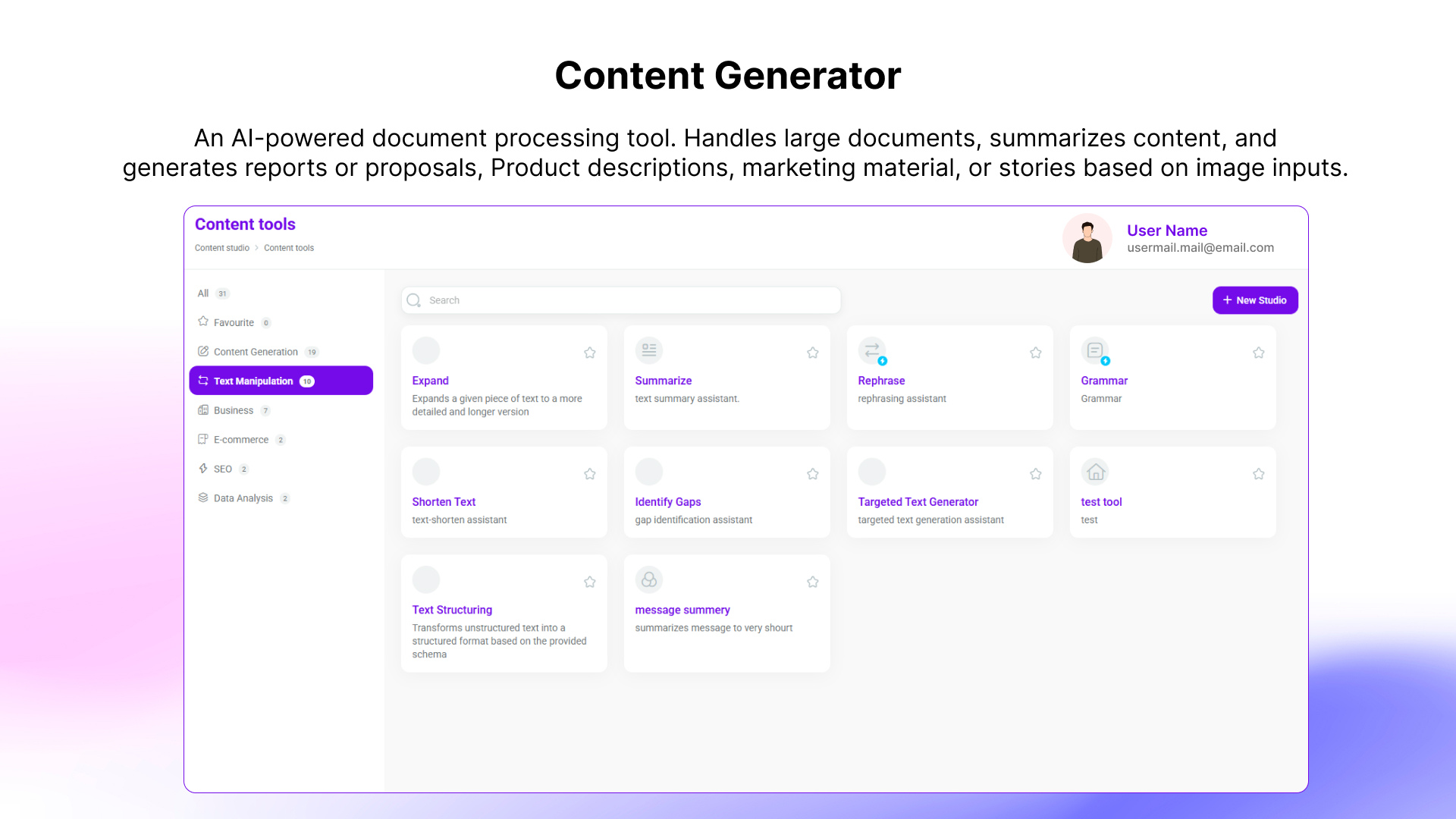
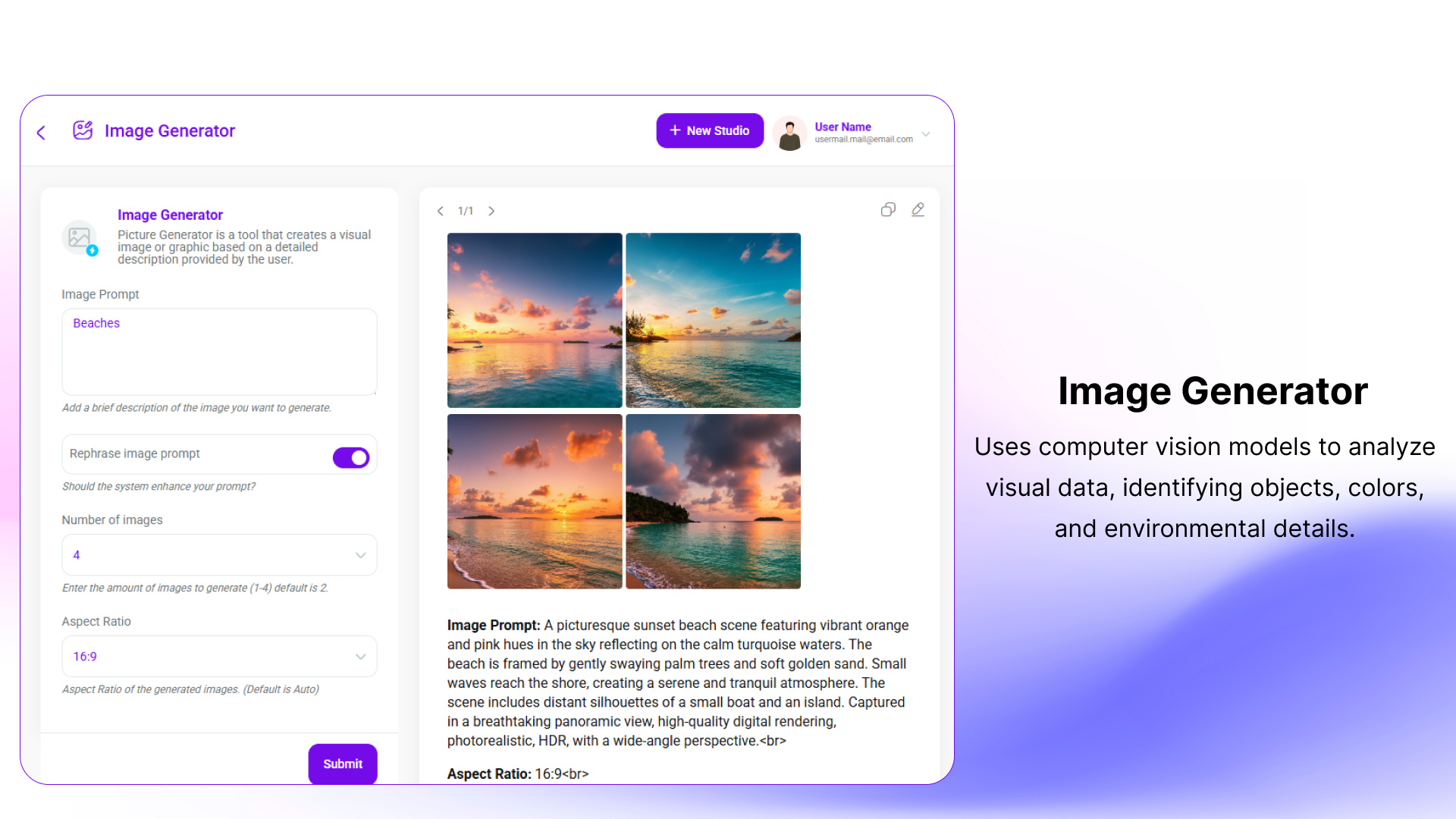
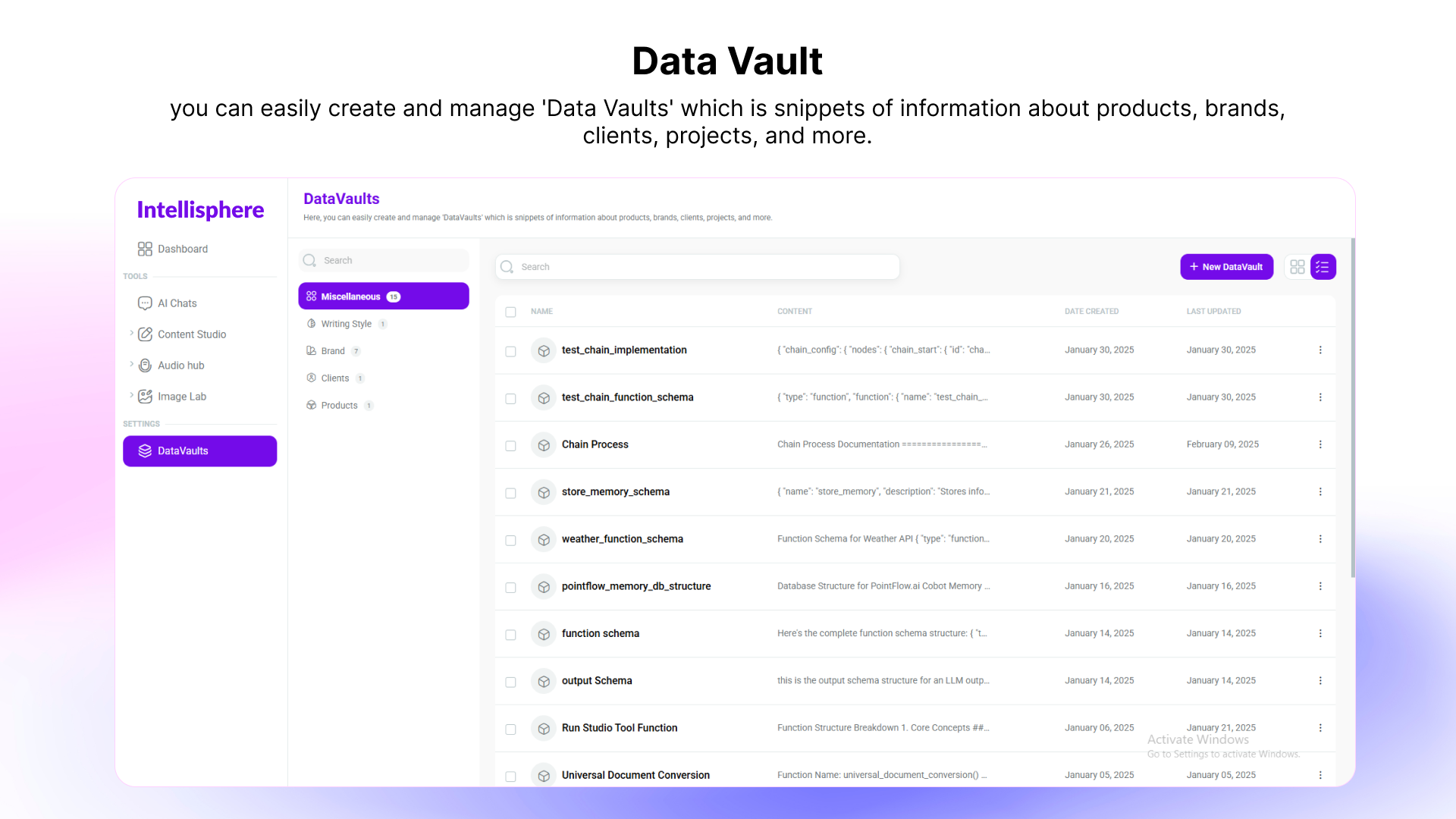
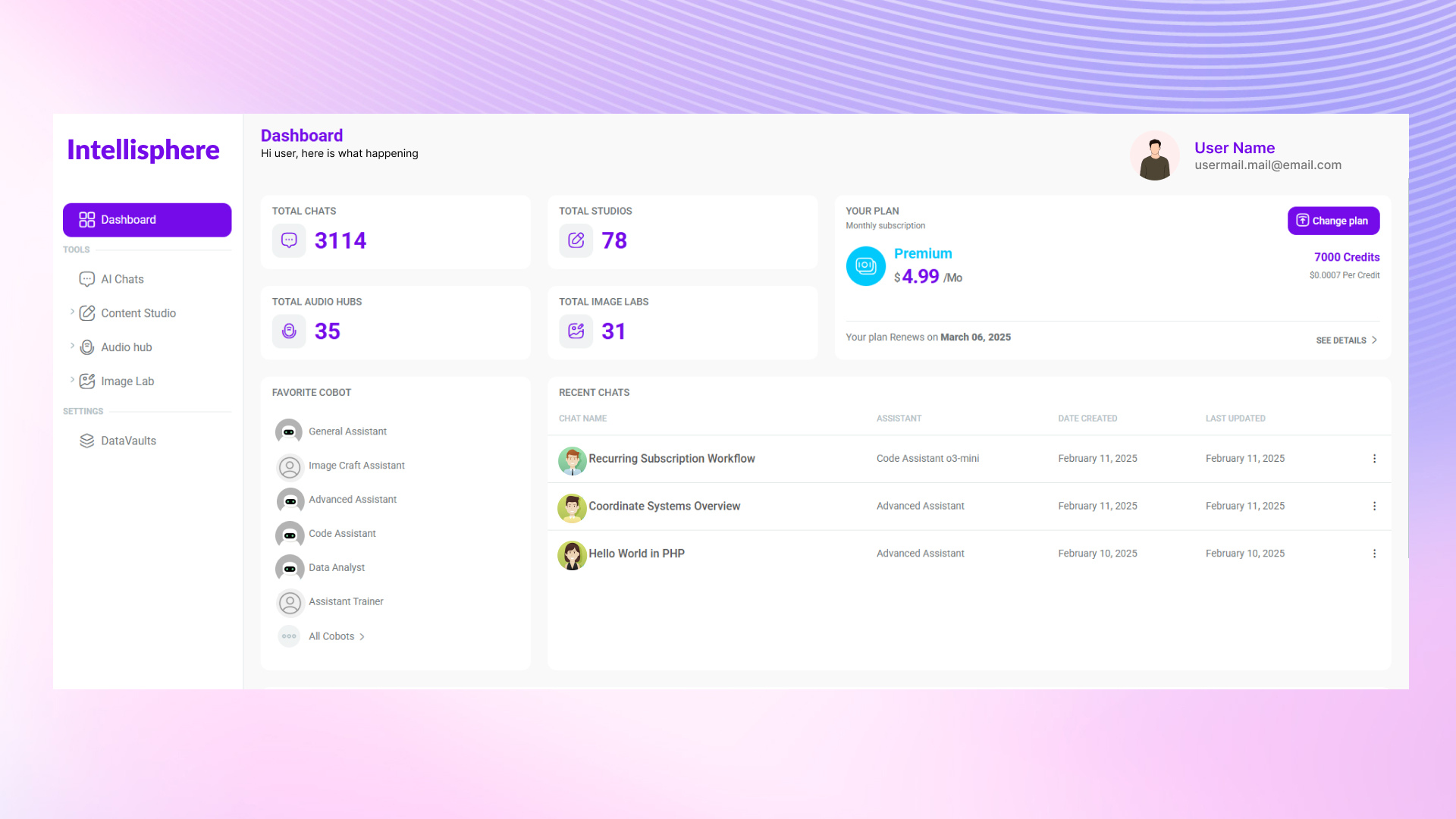
A generative AI platform where CoBots handle the complexity, so you can turn ideas into documents, visuals, and code no prompt-engineering required.
Intellisphere is a generative-AI platform that abstracts away the need for prompt-engineering. In short: no more wrestling with how to ask the “right” prompt. You tell it what you want, and the system’s CoBots (“collaborative robots”) work with you to fill in missing details, then deliver interactive, usable output. The aim is to enable non-experts to get meaningful, polished results such as documents, visuals, and code without needing deep AI or technical knowledge.
"Work-done" approach, rather than "teach me to prompt": you state a desired outcome; the system prompts you for missing pieces if needed (like a human collaborator would).
Team of specialized CoBots:
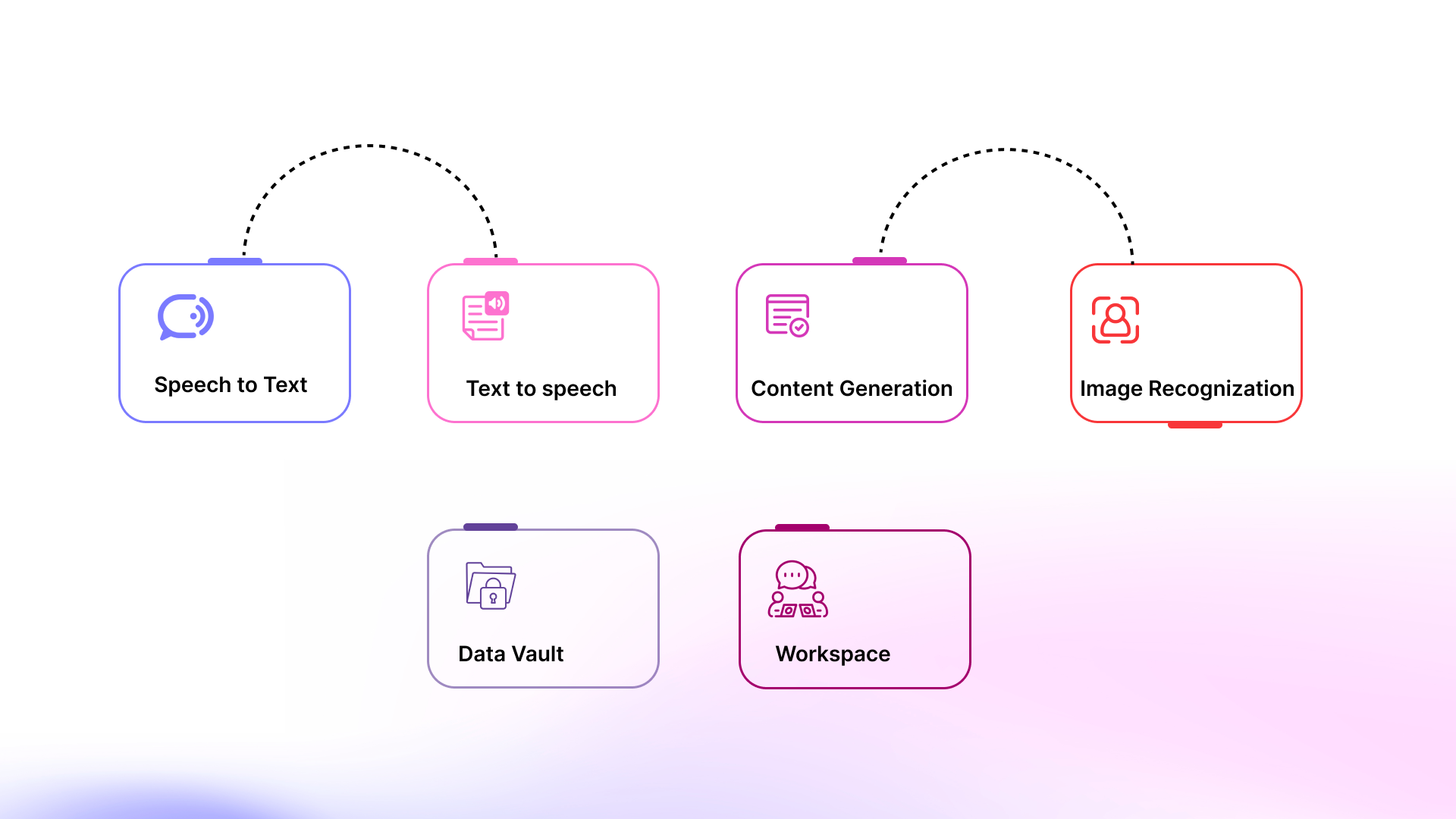
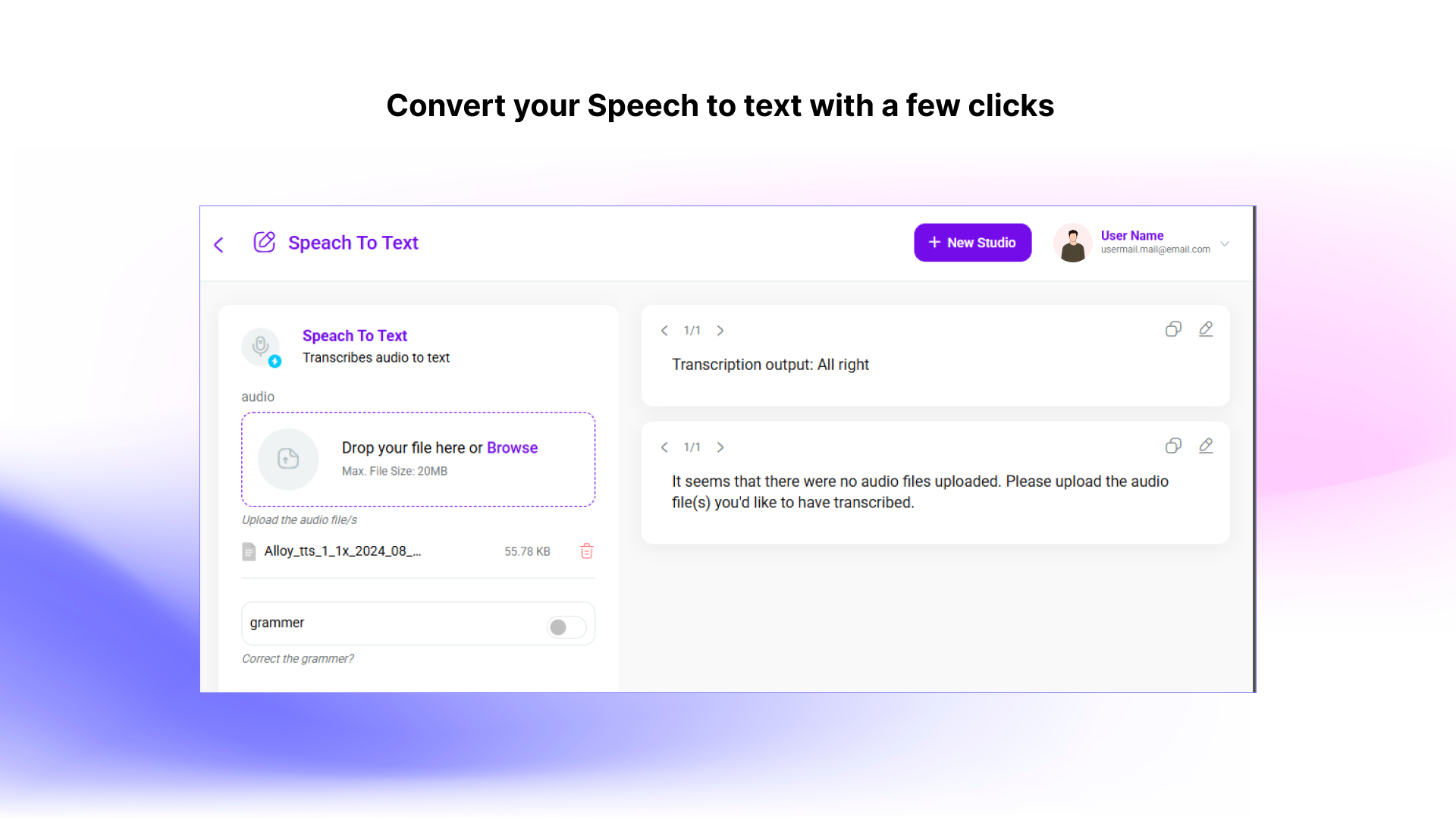
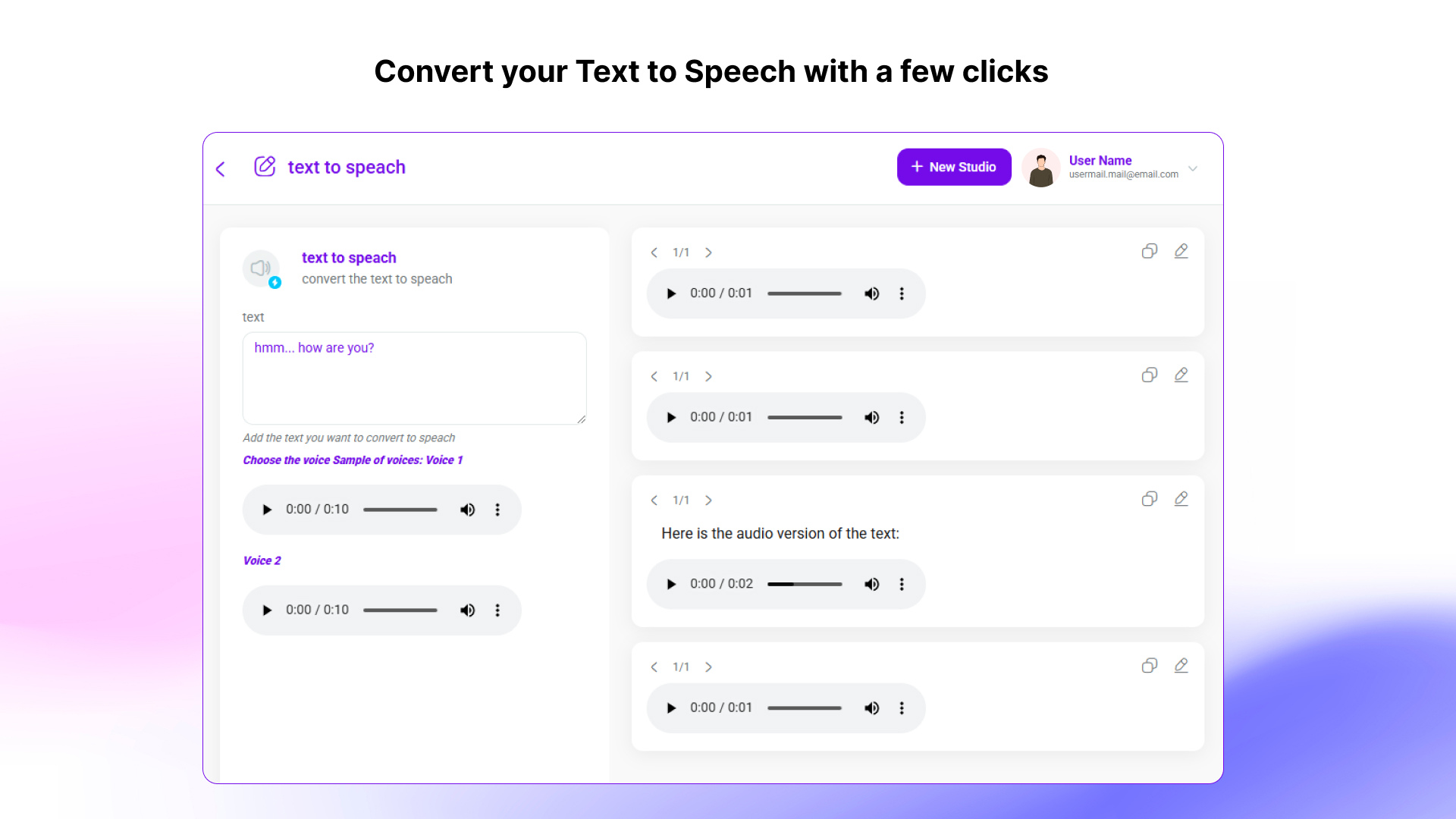
The client wanted to build a system that:
Industry studies show that poor information access costs enterprises up to $5M per year in lost productivity.
If removing those hidden productivity costs resonates with you, we can model the potential ROI for your team.The problems that prompted this development:
Traditional keyword search fails 35–40% of the time for knowledge retrieval, leaving users frustrated and slowing decisions.
We can audit your current knowledge flows and highlight exactly where intelligent retrieval would cut delays.Here’s what was built and how:
Vector search + RAG pipelines improve context relevance by over 80%, reducing hallucinations and boosting trust in answers.
Companies deploying conversational AI see a 25–40% drop in routine support queries and significantly faster resolution times.
We built a GenAI chatbot system that combines RAG, vector search, LLMs, and modular tool use to provide a fast, accurate, and context-aware conversational experience.
The result: A scalable, technically solid backend that supports a responsive frontend; meaningful reduction in manual effort; and higher user satisfaction through better answers and maintained dialogue context.
Curious to see how this kind of GenAI architecture can transform your own documents and support workflows, reducing response times, increasing accuracy, cutting support costs? Let’s sketch a custom proof-of-concept (on your content + your data) and we’ll show you by your numbers what the gains look like.
Get to Know Our ExpertiseThe AT team was very professional and always readily available to assist. The final result of my website was exactly what I was looking for. They’re highly skilled in all aspects of WordPress design and storefront development, including payment gateway integration. I’d highly recommend them to anyone looking for a developer for a similar project.

Very happy with the team’s quality of work. Will definitely hire them again.

They’ve put in a lot of hard work on our project, and it is very much appreciated.

Great work on this Laravel development project. I enjoyed working with them — communication was top-notch, all deadlines were met, and their skills were solid.
We completed all work as planned. ArsenalTech is an excellent company with skilled developers and designers who work hard, even on challenging tasks. We're still working with them and have long-term plans for future projects. Great work as always! Finished on time. We’ll continue collaborating on future projects. Definitely among the top talent on Upwork.

Mehul and his team did a great job at managing these project tasks. Unfortunately, we had to cancel early due to budget reasons but otherwise we would have been glad to continue working with Mehul. Thanks for the great work you provided and positive attitude that you brought to work everyday.

Team ArsenalTech was always professional and supported me with everything I needed. In addition to their technical expertise, they also demonstrated integrity and strong values. Great work by a great team!


Let’s sketch your proof-of-concept. See how context-rich GenAI, CoBots, and vector search can cut support costs, increase accuracy, and speed up every business process.