

Introduction
Retrieval-Augmented Generation (RAG) is the practical pattern that makes large language models (LLMs) useful for production SaaS: it combines runtime retrieval of relevant documents with LLM generation so answers are current, auditable, and tailored to your tenant’s data.
This guide gives you a multi-cloud, multi-tenant architecture, hands-on quickstarts (LangChain, LlamaIndex, and a framework-agnostic flow), operational checklists, compliance notes for USA & EU, and an FAQ section optimized for real product decisions.
If you want to explore how we implement RAG in real SaaS products, check how we do it here.
Why RAG Matters for SaaS (Strategy & Economics)
Founders and CTOs often face the same decision: fine-tune an LLM to bake in knowledge, or use RAG to retrieve knowledge at runtime. RAG wins for many SaaS use-cases because:
- Freshness: Documents change (contracts, policies, product specs). RAG surfaces current data without retraining.
- Cost & Speed: Fine-tuning is expensive and slow. RAG reduces the need for frequent model retraining.
- Explainability: By returning source snippets and metadata, RAG provides audit trails essential for regulated customers.
- Personalization: Per-tenant documents, metadata filters, and business rules allow tenant-aware responses without bespoke models.
If you’re considering adding a tenant-aware knowledge assistant to your SaaS, hire us to architect it for you — we’ve deployed these multi-tenant RAG systems in production.
Tradeoffs: RAG reduces hallucination risk but doesn’t eliminate it. Retrieval quality depends on embeddings, chunking strategy, and index hygiene. Plan for human-in-the-loop verification for high-stakes outputs.
Core RAG Pipeline
- Ingestion: extract data (docs, DB rows, support transcripts), clean, chunk, and embed.
- Indexing: store embeddings and metadata in a vector store with appropriate access controls.
- Retrieval: given a query, fetch top-k semantically relevant chunks, optionally apply metadata/tenant filters.
- Generation: construct a prompt (system + retrieved context + user question), call the LLM, and post-process with citation and safety checks.
Multi-Tenant SaaS Architecture
Design goals: tenant isolation, cost efficiency, region compliance, and operational visibility.
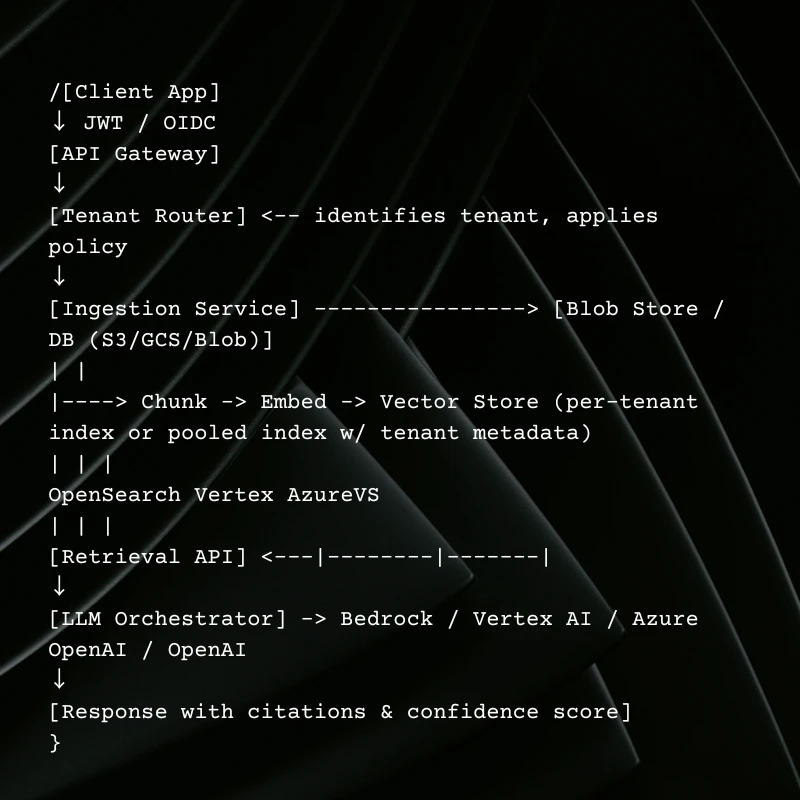
Tenant Isolation Patterns
- Silo: separate index per tenant, strongest isolation, higher cost. Good for large enterprise customers or strict compliance.
- Pool: single shared index with tenant metadata and filters, cost-efficient for many small tenants.
- Bridge (Hybrid): pooled indices for most tenants, per-tenant indices for enterprise ones.
Choose based on SLAs, compliance, and cost. For customers who require data residency, provision indices and ensure embeddings & raw docs stay within EU boundaries. If this design sounds complex, see how we build these SaaS-ready RAG architectures for scale and compliance.
Multi-Cloud Considerations (AWS, GCP, Azure)
- AWS: Bedrock (LLM access) + OpenSearch or Kendra for vector + S3 for storage. Offer region-specific indices via separate OpenSearch domains or prefixes.
- GCP: Vertex AI (LLMs) + Vertex vector search + GCS. Good telemetry and integrated IAM.
- Azure: Azure OpenAI + Cognitive search vector + blob storage. Tight integration with Microsoft enterprise identity.
Multi-cloud benefits: vendor choice for enterprise clients, region-specific data residency, and failover.
Operational cost: added complexity in deployment and observability, centralize monitoring and metrics.
Quickstart Code — Ingest → Retrieve → Generate
Below are compact, conceptual quickstarts. Replace provider keys and endpoints for production.
LangChain (Python)
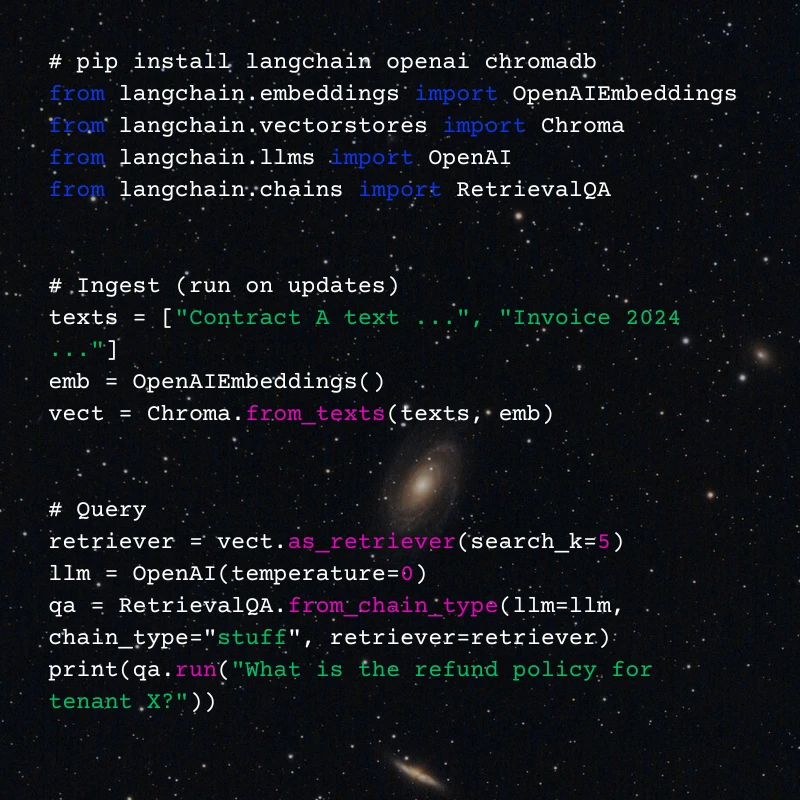
Notes: tune search_k, chunk sizes (200–500 tokens), and embedding model for cost/quality tradeoffs.
LlamaIndex (Python)
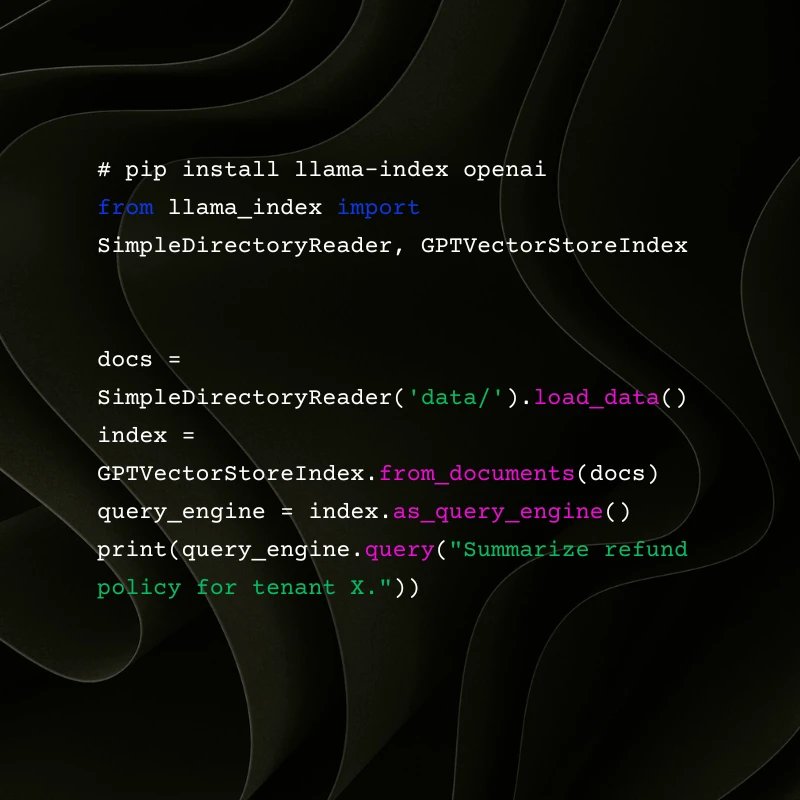
Notes: LlamaIndex simplifies doc-first workflows; pair with vector store of choice for scale.
Framework-Agnostic (Pseudo)

Notes: Always include source links, chunk offsets, and a confidence score in the UI.
Operational Checklist
- Index refresh policies: schedule full reindex for static corpora and stream updates for dynamic sources.
- Evaluation: maintain synthetic queries and golden answers to track retrieval precision/recall + downstream LLM accuracy.
- Monitoring: latency, cost per query, retrieval hit rate, top-k overlap, and hallucination incidents.
- Human-in-the-loop: flag low-confidence responses for review; provide an easy feedback loop.
- Feature flags: roll out RAG features gradually and gate by tenant.
Security, Privacy, and Compliance
- PII Handling: scrub or tokenize PII before embeddings if not required. Some providers treat embeddings as potentially reversible; follow vendor guidelines.
- Access Controls: enforce tenant ACLs at the vector store and API layers; audit every retrieval and generation call.
- Certifications: enterprise customers ask for SOC2/HIPAA/GDPR readiness — design for auditability and logs.
Future Trends (What to Watch)
- Reasoning-Augmented RAG: models that can chain-of-thought with retrieved facts, improving complex reasoning.
- Hybrid Tuning: mix lightweight fine-tuning for core behaviors plus RAG for data freshness.
- Edge + Regional Indexing: keeping latency low by placing indices closer to users, especially for EU & US enterprise customers.
Conclusion & Next Steps
RAG is the pragmatic bridge between powerful LLMs and real-world SaaS products.
For founders and CTOs: pick a tenant-isolation strategy, start small (one tenant or pooled index), instrument retrieval quality, and iterate.
- Turn the architecture into a one-page SVG with AWS/GCP/Azure callouts, or
- Scaffold a repo with LangChain + Chroma + example infra (Terraform for multi-region index provisioning).
Or, if you prefer not to go it alone, get help from our team to implement RAG in your SaaS.
Developer Tips & Insights

Building a HIPAA-safe Patient Dashboard with Next.js + Node.js- powered by Brightree data through MuleSoft
